Simple Word2Vec implementation in PyTorch

Introduction
One of the most important steps in solving NLP tasks using AI is finding a way to convert “words,” which humans can understand, into numbers, which computers and neural networks can understand. There are many ways to achieve this, but the challenge lies in preserving the meaning and significance of words without losing information in the process.
In this article, we’ll explore word2vec, an approach developed in 2013 by Tomas Mikolov and colleagues at Google to generate vector representations of words. These vectors capture the meaning and relationships of words based on their surrounding context.
It’s worth noting that Word2Vec may not be the best approach to obtain word embeddings anymore. With the rapid development in AI, more efficient and better approaches have been created, such as BERT, which utilizes Transformer architecture and can preserve more information while computing the embeddings, including the context within the sentence, something that Word2Vec isn’t able to do.
Word2Vec generates a fixed vector for the same word, regardless of its position in a sentence, unlike BERT, which generates different vectors for the same word based on its context and position.
Architecture overview
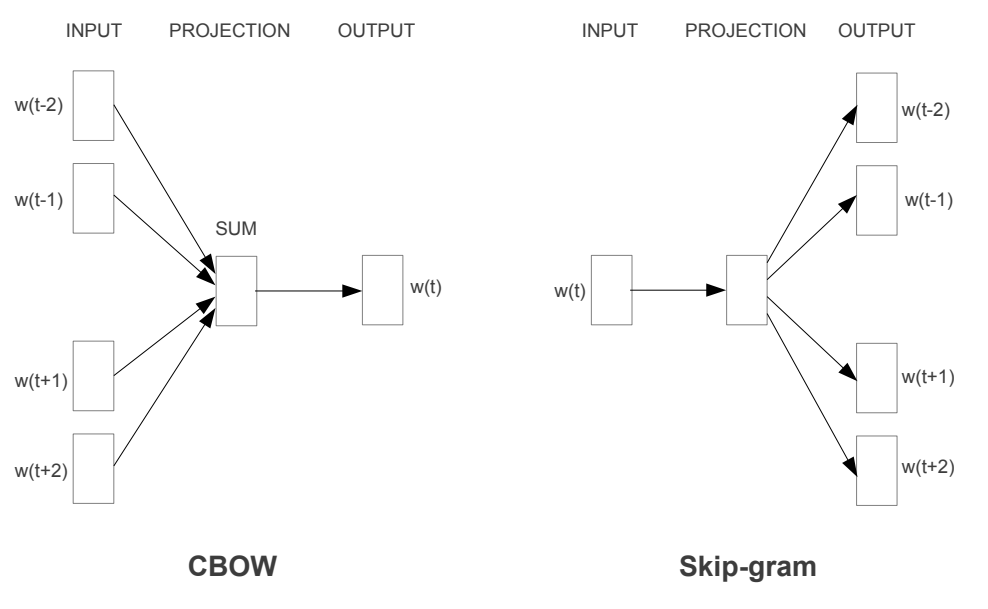 Source: Word2Vec paper
Source: Word2Vec paper
The paper suggests two approaches to implement Word2Vec:
- Continuous Bag of Words (CBoW): predicting the target/center word based on the neighbouring words.
- Skip Gram: predicting the context words based on the center word.
You might be wondering, why are we talking about predicting words here, since our main goal is to compute word embeddings? The trick is, by building a model to predict a word based on its surrounding words, we will find that the weights in the embedding layer are the learned vector representation of the words, which are the embeddings we are looking for.
In this article, we’ll be implementing a simplified version of Word2Vec using the CBOW approach. The model is very simple and has only two layers:
- Input layer: Takes one-hot encoded words as input.
- Linear layer: Using softmax activation we get probabilities of the predicted target word given its surrounding context words.
Data preparation
I’ve used wikipedia to get some text on different topics such as “Deep learning”, “biology”, “physics” .. and put the text into a single text file.
Let’s start by some basic text cleaning:
1
2
3
4
5
6
7
8
9
10
def clean_and_tokenize(text):
cleaned_text = re.sub(r'[^a-zA-Z]', ' ', text)
cleaned_text = re.sub(r'\s+', ' ', cleaned_text)
cleaned_text = cleaned_text.lower()
tokens = cleaned_text.split(' ')
with open("./stopwords-en.txt", "r") as f:
stop_words = f.read()
stop_words = stop_words.replace('\n', ' ').split(' ')
return [token for token in tokens if token not in stop_words][:-1]
tokens = clean_and_tokenize(data)
After reading the text for the file, we’ll remove any numbers, special characters and stopwords and then return the list of tokens (words in this case).
After that, We’ll need two dictionaries, one to get words given their Id and vice versa, this is needed later for things such as one hot encoding and getting embeddings of specific words.
1
2
3
unique_words = set(tokens)
word_id = {word:i for (i,word) in enumerate(unique_words)}
id_word = {i:word for (i,word) in enumerate(unique_words)}
Training Data
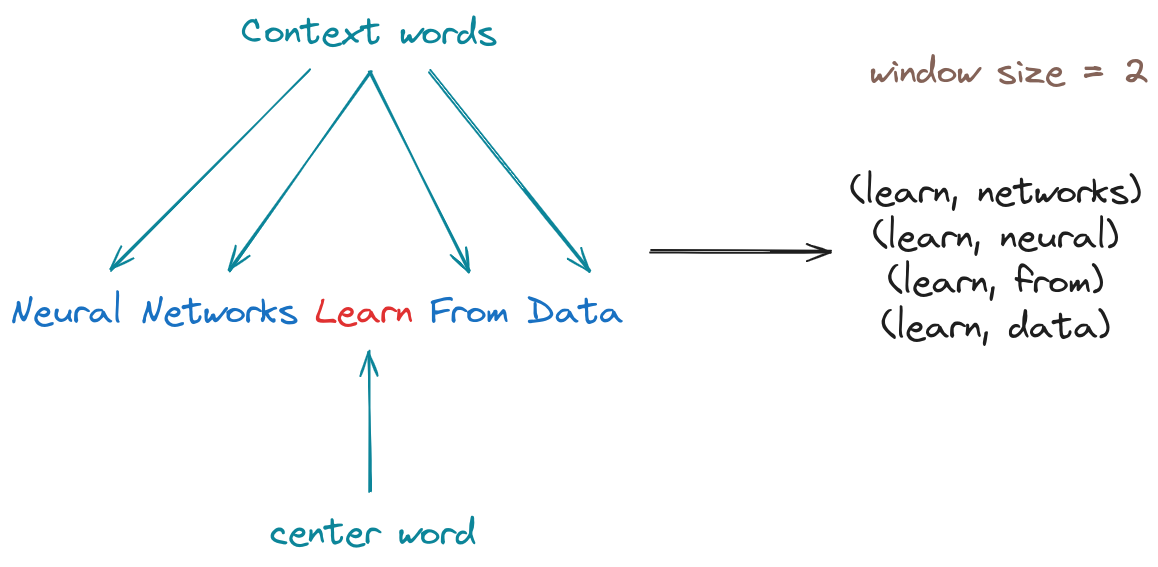
Let’s prepare a dataframe with two columns, where one column represents the center (target) word, and the other column represent all of it’s surrounding words (context) For this example, we’ll set a window size of 2. This means that for each center word, we’ll consider the two words to its left and the two words to its right as its context words.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
window_size = 2
def target_context_tuples(tokens, window_size):
context = []
for i, token in enumerate(tokens):
context_words = [t for t in merge(tokens, i, window_size) if t != token]
for c in context_words:
context.append((token, c))
return context
def merge(tokens, i, window_size):
left_id = i - window_size if i >= window_size else i - 1 if i != 0 else i
right_id = i + window_size + 1 if i + window_size <= len(tokens) else len(tokens)
return tokens[left_id:right_id]
For example, for this sentence: Deep learning is the subset of machine learning methods based on artificial neural networks, the result would be (after text cleaning):
1
2
target_context_pairs = target_context_tuples(tokens, 2)
target_context_pairs[:20]
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
[('deep', 'learning'),
('deep', 'subset'),
('learning', 'deep'),
('learning', 'subset'),
('learning', 'machine'),
('subset', 'deep'),
('subset', 'learning'),
('subset', 'machine'),
('subset', 'learning'),
('machine', 'learning'),
('machine', 'subset'),
('machine', 'learning'),
('machine', 'methods'),
('learning', 'subset'),
('learning', 'machine'),
('learning', 'methods'),
('learning', 'based'),
('methods', 'machine'),
('methods', 'learning'),
('methods', 'based')]
...
1
2
import pandas as pd
df = pd.DataFrame(target_context_pairs, columns=["target","context"])
Now let’s convert the words into one-hot encodings, we’ll use the one_hot() method from nn.functional.
1
2
3
4
5
6
7
8
9
import torch.nn.functional as F
import torch
vocab_size = len(unique_words)
token_indexes = [word_id[token] for token in unique_words]
encodings = F.one_hot(torch.tensor(token_indexes), num_classes=vocab_size).float()
df["target_ohe"] = df["target"].apply(lambda x : encodings[word_id[x]])
df["context_ohe"] = df["context"].apply(lambda x : encodings[word_id[x]])
Pytorch Dataset class
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
from torch.utils.data import Dataset
class W2VDataset(Dataset):
def __init__(self, df):
self.df = df
def __len__(self):
return len(self.df)
def __getitem__(self, idx):
context = df["context_ohe"][idx]
target = df["target_ohe"][idx]
return context, target
dataset = W2VDataset(df)
And for the dataloder, we’ll chose a batch size of 64
1
2
from torch.utils.data import DataLoader
dataloader = DataLoader(dataset, batch_size=64, shuffle=True)
Model
1
2
3
4
5
6
7
8
9
10
class Word2Vec(torch.nn.Module):
def __init__(self, vocab_size, embed_size):
super(Word2Vec, self).__init__()
self.linear1 = torch.nn.Linear(vocab_size, embed_size)
self.linear2 = torch.nn.Linear(embed_size, vocab_size, bias=False)
def forward(self, x):
x = self.linear1(x)
x = self.linear2(x)
return x
It makes more sense to use an Embedding layer instead of the first linear layer, but after doing some experiments on my own dataset, I found that using two linear layers gave me better results, so it all depends on the data, but generally nn.Embedding layer is more optimized for this kind of tasks.
Notice We didn’t use softmax after the output layer since the loss function that we’re going to use
CrossEntrepyLossalready uses a softmax activation function.
Training
For this example, we’ll use an embedding size of 10, but the original paper used an embedding size of 300.
We use the cross-entropy loss function to compute the loss between the predicted word probabilities and the actual target words during training. Additionally, the Adam optimizer is used to update the model parameters based on the computed gradients, with a learning rate of 0.01.
1
2
3
4
5
6
7
8
from torch import nn
device = 'cuda' if torch.cuda.is_available() else 'cpu'
EMBED_SIZE = 10
model = Word2Vec(vocab_size, EMBED_SIZE)
model.to(device)
LR = 1e-2
loss_fn = nn.CrossEntropyLoss()
optimizer = torch.optim.Adam(model.parameters(), lr=LR)
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
epochs = 300
loss_values = []
for epoch in range(epochs):
running_loss = 0.0
# model.train() # no need since model is in train mode by default
for batch, (context, target) in enumerate(dataloader):
context = context.to(device)
target = target.to(device)
optimizer.zero_grad()
pred = model(context)
loss = loss_fn(pred, target)
running_loss += loss.item()
loss.backward()
optimizer.step()
epoch_loss = running_loss/len(dataloader)
if (epoch+1)%10 == 0:
print(f"Epoch [{epoch + 1}/{epochs}], Loss: {epoch_loss}")
loss_values.append(epoch_loss)
Now that the model has finished training, let’s try to find the top 5 similar words to “language”.
1
2
3
4
word = encodings[word_id["language"]]
[id_word[id.item()] for id in torch.argsort(model(word.to(device)), descending=True).squeeze(0)[:5]]
#>['processing', 'recognition', 'natural', 'machine', 'language']
Let’s try other words:
1
2
3
4
life: ['study', 'organisms', 'earth', 'emerged', 'energy']
computer: ['fields', 'speech', 'vision', 'including', 'computer']
physics: ['nuclear', 'physicist', 'chemistry', 'often', 'called']
food: ['heat', 'preparing', 'fire', 'establishments', 'digestible']
Great, we can see that model successfully predicts the words that are close to the input word. But that’s not our final goal, our ultimate goal is to obtain the embeddings of each word, and we can achieve this by extracting the weights from the model.
1
2
3
4
5
6
7
8
def get_word_embedding(model, word):
embeddings = model.linear2.weight.detach().cpu()
id = word_id[word]
return embeddings[id]
get_word_embedding(model, "biology")
#> tensor([ 1.7960, -1.1708, 1.3297, -1.1629, 1.6046, -1.7291, 0.2075, 2.2238, 1.6542, 2.1732])
One of the characteristics of the learned word embeddings is that words with similar or close meanings are closer together in the embedding space, as stated in one of the famous examples mentioned in the Word2Vec paper:
vector(“King”) - vector(“Man”) + vector(“Woman”) results in a vector that is closest to the vector representation of the word Queen
Pretty cool right?
Conlusion
In this article, we learned how the famous Word2Vec model operates by making a simplified implementation in PyTorch, but it’s worth noting that a lot of improvements can be made. For example, the data processing steps we did can change depending on the use case; in some scenarios, it would be beneficial to keep numbers and compute embeddings for them as well instead of removing them from the corpus. Also, you might want to try with larger embedding dimensions as it may help the model to capture more information for each word.
Here’s the github repo for all the code + data used in this article.
References
I’ll leave you with some great articles that go into more detail on the workings of Word2Vec.