Use custom LLMs from Hugging Face locally with Ollama

Introduction
Since the release of ChatGPT, we’ve witnessed an explosion in the world of Large Language Models (LLMs). Almost every day a new state of the art LLM is released, which is fascinating, but difficult to keep up with, particularly in terms of hardware resource requirements.
Running a powerful LLM locally demands increasingly substantial resources, making it expensive to set up, especially with the need for high-end GPUs. Fortunately, there are techniques available to make running these models locally feasible, such as model quantization.
Model quantization is a technique that involves reducing the precision of a model’s weights (e.g., float32 –> int8) leading to a reduction in computational costs. (learn more)
Two notable quantization methods in Large Language Models (LLMs) are GPTQ, a 4-bit quantization designed for efficient GPU inference, and GGUF, which primarily utilizes CPU resources with minimal GPU usage
Thanks to TheBloke on Huggine Face, we can easily find a variety of ready to use quantized models in different formats, all we have to do is choose the model that fits our hadrware configuration.
 Quantized models by Thebloke
Quantized models by Thebloke
In this article, we’ll go through the steps to setup and run LLMs from huggingface locally using Ollama.
Let’s get started
For this tutorial, we’ll work with the model zephyr-7b-beta and more specifically zephyr-7b-beta.Q5_K_M.gguf
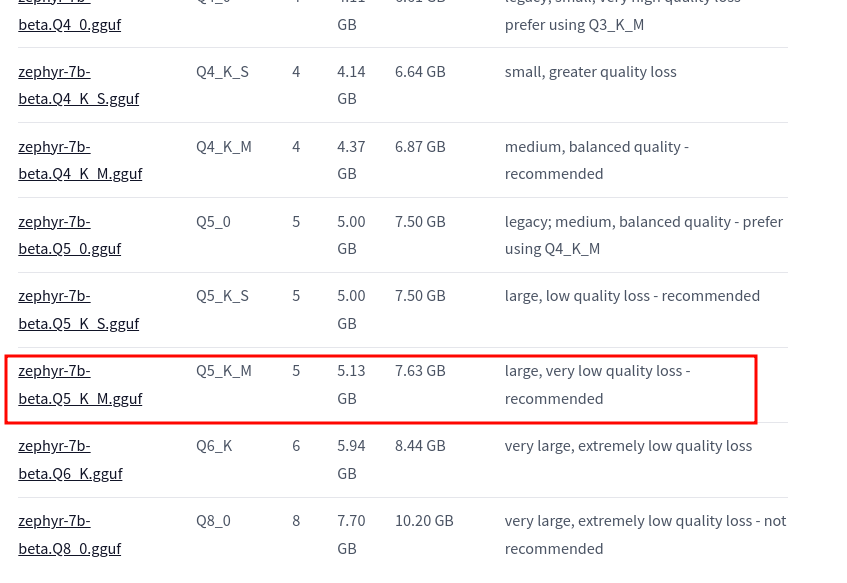
1. Downloading the model
To download the model from hugging face, we can either do that from the GUI

or by using the hugging face CLI
1
huggingface-cli download TheBloke/zephyr-7B-beta-GGUF zephyr-7b-beta.Q5_K_M.gguf --local-dir models/ --local-dir-use-symlinks False
In the command above, we had to specify the user (TheBloke), repository name (zephyr-7B-beta-GGUF) and the specific file to download (zephyr-7b-beta.Q5_K_M.gguf).
2. Installing Ollama
Ollama is a tool that helps us run llms locally. The Ollama library contains a wide range of models that can be easily run by using the commandollama run <model_name>
On Linux, Ollama can be installed using:
1
curl https://ollama.ai/install.sh | sh
3. Creating Modelfile
Modelfile is where we add our model’s parameters and instructions.
So let’s create a Modelfile with the following content:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
FROM models/zephyr-models/zephyr-7b-beta.Q5_K_M.gguf
PARAMETER num_ctx 3900
PARAMETER temperature 0.7
PARAMETER top_k 50
PARAMETER top_p 0.95
PARAMETER stop "<|system|>"
PARAMETER stop "<|user|>"
PARAMETER stop "<|assistant|>"
PARAMETER stop "</s>"
TEMPLATE """
<|system|>\n system
{{ .System }}</s>
<|user|>\n user
{{ .Prompt }}</s>
<|assistant|>\n
"""
SYSTEM """You are an assistant for PhD researchers, you help them find infos from research papers at ease."""
Note that certain parameters may vary from one model to another; for instance, the STOP and TEMPLATE parameters values are specific to this model and can be located on Zephyr’s page.
4. Build the model with Modelfile
1
ollama create zephyr-local -f Modelfile
We can see the list of the created models using:
1
ollama list
5. Run the model
Lastly, we can run the model using:
1
ollama run zephyr-local
Let’s see if the model respected the parameters in the Modelfile:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
>>> What are you useful for?
As an AI language model, I can assist you in various ways such as:
1. Summarizing research papers: I can provide a concise summary or key
points of a research paper based on your requirements. This helps you to
quickly understand the main ideas and findings of the paper without having
to read it in full.
2. Finding relevant information: If you're looking for specific
information related to a particular topic, I can search through a large
number of research papers and extract the required information for you.
3. Answering questions: You can ask me any question related to your
research area, and I will provide an accurate and detailed answer based on
my extensive knowledgebase.
4. Providing suggestions: If you're struggling with a specific research
problem or need some ideas for your next study, I can suggest potential
approaches or methods that might be helpful.
5. Editing and proofreading: I can help you to improve the clarity and
coherence of your own writing by checking for grammatical errors,
suggesting alternative phrasing, and ensuring that your arguments are
logical and well-supported.
Looks good!
In case we want to delete the model, we simply run:
1
ollama rm zephyr-local
That’s it! We succesffuly run a powerfull LLM locally without the need of expensive GPUs.