Dockerizing a RAG Application with FastAPI, LlamaIndex, Qdrant and Ollama

Introduction
In the previous article, we built a local RAG api using FastAPI, LlamaIndex and Qdrant to query documents with the help of a local LLM running via Ollama.
While the application worked locally, setting it up each time, installing dependencies, ensuring the right versions in the right environment, running background services..quickly became tedious and error-prone.
In this post, we’ll walk through how we Dockerized the entire setup to make it fully containerized, reproducible, and easy to deploy with a single command. By the end, we’ll have a clean multi-service Docker Compose setup running this RAG app in isolated containers.
Project Structure Overview
So far this is the project structure of our project:
1
2
3
4
5
6
7
8
9
10
├── api/ # FastAPI app
│ ├── main.py # FastAPI entry point
│ └── rag.py # RAG logic, used by the api
├── data/ # Data ingestion / document handling
│ ├── data.py # Script to download, load and process documents
├── ollama/ # Local model setup with Ollama
│ ├── Modelfile # Ollama model definition (e.g., Zephyr, llama2, mistral)
│ └── run_ollama.sh # Script to start Ollama and serve the model
├── pyproject.toml # Project metadata and dependencies
└── uv.lock # Lockfile with pinned dependency versions
Creating Dockerfiles
Dockerfiles contains the instructions on how to build the image, such as: base image, dependencies and commands to run.
To dockerize our entire application, we need to create a Dockerfile for each service.
In our case, we need to build two custom images:
- API image
- Data ingestion tool image
For Qdrant & Ollama, we only need to pull the official images and run them directly.
- Qdrant image: https://hub.docker.com/r/qdrant/qdrant
- Ollama image: https://hub.docker.com/r/ollama/ollama
Let’s first ensure our dependencies are defined correctly. Since we are using uv and pyproject.toml file to manage dependencies, the typical setup looks like this:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
[project]
name = "local-rag-llamaindex"
version = "0.1.0"
description = "Local llamaindex RAG api to assist researchers quickly navigate research papers"
readme = "README.md"
requires-python = ">=3.13"
dependencies = [
"arxiv>=2.2.0",
"fastapi[standard]>=0.115.12",
"langchain>=0.3.24",
"langchain-community>=0.3.22",
"llama-index>=0.12.33",
"llama-index-embeddings-huggingface>=0.5.3",
"llama-index-embeddings-langchain>=0.3.0",
"llama-index-llms-ollama>=0.5.4",
"llama-index-vector-stores-qdrant>=0.6.0",
"ollama>=0.4.8",
"pydantic>=2.11.3",
"pyyaml>=6.0.2",
"qdrant-client>=1.14.2",
"sentence-transformers>=4.1.0",
"structlog>=25.3.0",
"tqdm>=4.67.1",
]
One challenge is that a typical Dockerfile requires installing the necessary dependencies, which means copying the pyproject.toml file and installing everything listed in it.
However, since we only have a single dependencies file, and each service uses both common and unique libraries, it’s not a good practice to install all dependencies, including unused ones into every Docker image we build.
To address this, we’ll separate the dependencies as follows:
- Shared dependencies: Used by both services, e.g.,
llama-index,qdrant-client, etc. These will go into a base image. - API specific dependencies: e.g.,
FastAPI,ollama, etc. - Data ingestion tool dependencies: e.g.,
arxiv, etc.
To do that, we’ll keep the shared depedencies in the main dependencies section, and the service-specific ones under [project.optional-dependencies] in pyproject.toml:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
[project]
name = "local-rag-llamaindex"
version = "0.1.0"
description = "Local llamaindex RAG api to assist researchers quickly navigate research papers"
readme = "README.md"
requires-python = ">=3.13"
dependencies = [
"hf-xet>=1.0.5",
"llama-index>=0.12.33",
"llama-index-embeddings-huggingface>=0.5.3",
"llama-index-llms-ollama>=0.5.4",
"llama-index-vector-stores-qdrant>=0.6.0",
"python-dotenv>=1.1.0",
"pyyaml>=6.0.2",
"qdrant-client>=1.14.2",
"sentence-transformers>=4.1.0",
"structlog>=25.3.0",
]
[project.optional-dependencies]
data_ingest = [
"arxiv>=2.2.0",
]
api = [
"fastapi[standard]>=0.115.12",
"pydantic>=2.11.3",
"ollama>=0.4.8",
]
Base Image
This image will include all shared dependencies, mainly llama-index packages, qdrant and sentence-transformers, and it will be used as the base for both the API and data ingestion images.
1
2
3
4
5
6
7
FROM ghcr.io/astral-sh/uv:python3.13-bookworm-slim
WORKDIR /app
COPY pyproject.toml uv.lock ./
RUN uv sync
We’re starting from the official uv image, which comes with python3.13 and uv pre-installed. It is a good starting point since we’ll be using pyproject.toml and uv for managing dependencies.
Next, we setup a working directly, in this case we called it app/ and then we copy our .toml and .lock files into it
Finally, we run the command uv sync to install all the dependencies inside our container with the versions matching the ones from the lock file.
API Image
1
2
3
4
5
6
7
8
9
10
11
FROM rag-base-image
WORKDIR /api
COPY pyproject.toml uv.lock ./
RUN uv pip install --system ".[api]"
COPY api/ .
CMD ["fastapi", "run", "main.py", "--port", "80", "--host", "0.0.0.0"]
We start by using the base image we just created, meaning we won’t have to reinstall all the comon dependencies. Then we set /api as our working directory, so any relative paths after (e.g., in COPY instructions) will be based on that directory.
We then install the api specific dependencies, found in pyproject.toml file under [project.optional-dependencies] , in the “api” section
After that we copy the local api/ folder to the api/ directory inside the container.
Finally, we start the fastapi server on port 80.
Docker builds each instruction into an intermediate layer. If a layer hasn’t changed since the last build, Docker caches it, meaning it won’t re-run that step
If we only change the app code in api/, Docker won’t re-install dependencies, it’ll reuse the cached layer above.
That’s why we install dependencies before copying the project code: to avoid reinstalling packages every time we modify the code.
Data ingestion image
1
2
3
4
5
6
7
8
9
10
11
FROM rag-base-image
WORKDIR /app
COPY pyproject.toml uv.lock ./
RUN uv pip install --system ".[data_ingest]"
COPY data/ .
ENTRYPOINT ["uv", "run", "data.py"]
This one is a bit similar to the api image, but this time we install the “data_ingest” section dependencies, copy the data/ folder to the app/ directory in the container, then run the script with uv run data.py
Ollama image
For Ollama, we’ll directly use a prebuilt image ollama/ollama:latest, and since we want it to use a local llm with our created Modelfile, we need to prodive some instructions to copy the correct file and run the LLM we created.
We’ll do that with the help of a simple bash script that will be used later in our docker compose file.
Qdrant image
Same as Ollama, we’ll use the prebuilt image qdrant/qdrant
Now that we have all our Dockerfiles ready, let’s go ahead and create a Docker Compose file that will orchestrate our multi-container setup.
Docker Compose
Now that each component of our RAG system has its own Dockerfile and image, it’s time to bring them all together.
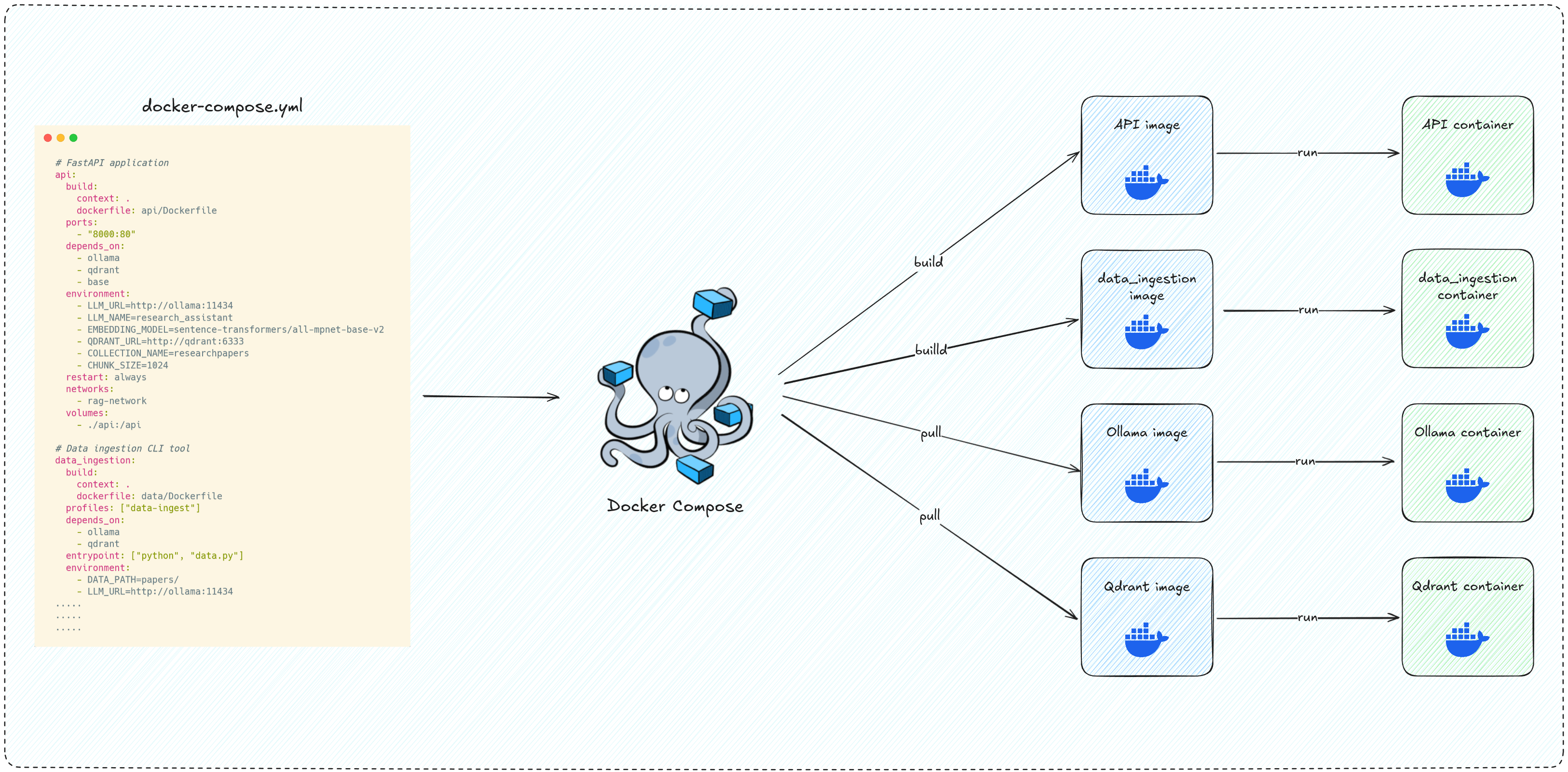
In this section, we’ll define a docker-compose.yml file that orchestrates the entire setup, allowing us to spin up the FastAPI API, Ollama model server, Qdrant vector database, and our data ingestion tool all at once with a single command.
Building the Base image
1
2
3
4
5
6
services:
base:
build:
context: .
dockerfile: Dockerfile.base
image: rag-base-image*
This service builds a base image that contains all shared dependencies across our project. The api and data_ingestion services will reference this image in their own builds.
This approach keeps the builds fast by avoiding repeated dependency installations across services
Api service
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
api:
build:
context: .
dockerfile: api/Dockerfile
ports:
- "8000:80"
depends_on:
- ollama
- qdrant
- base
environment:
- LLM_URL=http://ollama:11434
- LLM_NAME=research_assistant
- EMBEDDING_MODEL=sentence-transformers/all-mpnet-base-v2
- QDRANT_URL=http://qdrant:6333
- COLLECTION_NAME=researchpapers
- CHUNK_SIZE=1024
restart: always
networks:
- rag-network
volumes:
- ./api:/api
This runs our main RAG API built with FastAPI, exposing it on localhost:8000. It depends on the base image, as well as the ollama and qdrant services, meaning docker compose won’t start this service unless the other services are ready.
Data ingestion tool
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
data_ingestion:
build:
context: .
dockerfile: data/Dockerfile
profiles: ["data-ingest"]
depends_on:
- ollama
- qdrant
entrypoint: ["python", "data.py"]
environment:
- DATA_PATH=papers/
- LLM_URL=http://ollama:11434
- LLM_NAME=research_assistant
- EMBEDDING_MODEL=sentence-transformers/all-mpnet-base-v2
- QDRANT_URL=http://qdrant:6333
- COLLECTION_NAME=researchpapers
- CHUNK_SIZE=1024
networks:
- rag-network
volumes:
- ./papers:/app/papers
This is a one-off job or service used to load and embed documents into Qdrant, we don’t need this container to be continously runnning unless we start it, load and embed the documents into our vector database and then turned off.
Qdrant service
1
2
3
4
5
6
7
8
qdrant:
image: qdrant/qdrant
ports:
- "6333:6333"
volumes:
- ~/qdrant_storage:/qdrant/storage:z
networks:
- rag-network
Runs the Qdrant vector DB, which stores the chunked and embedded documents locally. It exposes port 6333 and persists data using the specified volume on our machine.
Ollama service
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
ollama:
image: ollama/ollama:latest
pull_policy: always
container_name: ollama
volumes:
- ./ollama:/model_files
- ./ollama:/root/.ollama
tty: true
entrypoint: ["/bin/sh", "./model_files/run_ollama.sh"]
environment:
- LLM_NAME=research_assistant
restart: always
extra_hosts:
- host.docker.internal:host-gateway
deploy:
resources:
reservations:
devices:
- driver: nvidia
count: all
capabilities: [gpu]
ports:
- "11434:11434"
networks:
- rag-network
This runs the Ollama LLM server locally and exposes it on port 11434. It runs a custom run_ollama.sh script to load the desired model.
1
2
3
4
5
6
7
8
9
10
11
12
13
#!/bin/bash
echo "Starting Ollama server..."
ollama serve & # Start Ollama in the background
echo "Ollama is ready, creating the model..."
if [ -z "$LLM_NAME" ]; then
echo "Error: LLM_NAME environment variable is not set."
exit 1
fi
ollama create $LLM_NAME -f ./model_files/Modelfile
ollama run $LLM_NAME
We added gpu configuration so Ollama can access it, For more details, see the official guide: Enable GPU access with Docker Compose
Network and Volumes
1
2
3
4
5
6
7
networks:
rag-network:
driver: bridge
volumes:
qdrant_storage:
ollama:
rag-network: A shared bridge network so services can talk to each other by name, eg:ollama:11434volumes: Declares named volumes used by services in order to persist data between runs.
You can find the full docker-compose.yml file here: docker-compose.yml
What’s left to do now is build the images and run the containers:
1
docker compose up ollama qdrant api
That’s it, the command will build the base image, start Qdrant and Ollama services, then start the API service.
Then if we want to ingest more documents into our vector database:
1
docker compose run data_ingestion --query "LLMs" --max 10 --ingest
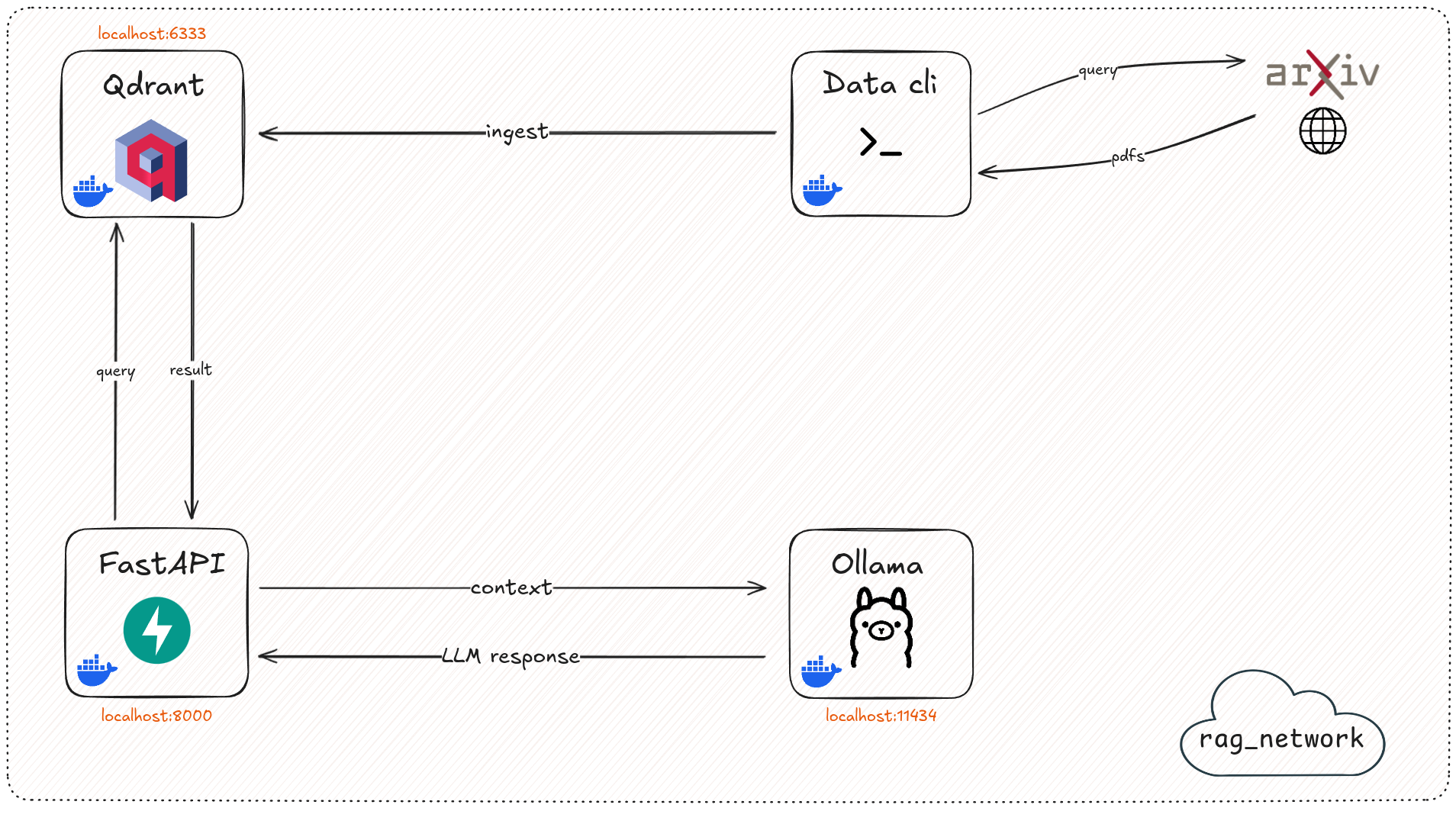
Api is now running on: http://localhost:8000/docs
Ollama: http://localhost:11434/
Qdrant ui: http://localhost:6333/dashboard#/collections
Finally, to stop all running containers and networks started by Docker Compose:
1
docker compose down
If we want to reset everything, including removing volumes (like Qdrant’s stored vectors) and networks, run:
1
docker compose down --volumes --remove-orphans
Conclusion
In this article, we learned how to dockerize a RAG application built with FastAPI, Llamaindex, Qdrant and locally served model via Ollama.
Explore the full project on Github repository