Building a Local RAG api with LlamaIndex, Qdrant, Ollama and FastAPI

Introduction
ChatGPT has changed the way we interact with AI. People now use these Large Language Models (LLMs) as primary personal assistants for writing, brainstorming, and even consulting. However, the problem with these LLMs is that they are only as good as the data they are trained on. For example, if a company wanted to query ChatGPT about an internal document, ChatGPT wouldn’t be able to understand it. Additionally, its knowledge may not be up to date, and it is prone to hallucination.
To address this issue, we can fine-tune these LLMs on our data so they can answer questions from it. However, this approach can be very expensive. Keeping them updated with new information requires constant retraining. Moreover, the problem of hallucination remains, and it’s difficult to verify the sources of their answers.
A better approach would be to leverage powerful LLMs with access to our data without fine-tuning. How can we achieve this? Thanks to a recently emerged approach called Retreival Augmented Generation (RAG), we can retrieve relevant documents related to the user query and feed them as additional context to the LLM to generate the answer. (More details will be discussed in the next sections.)
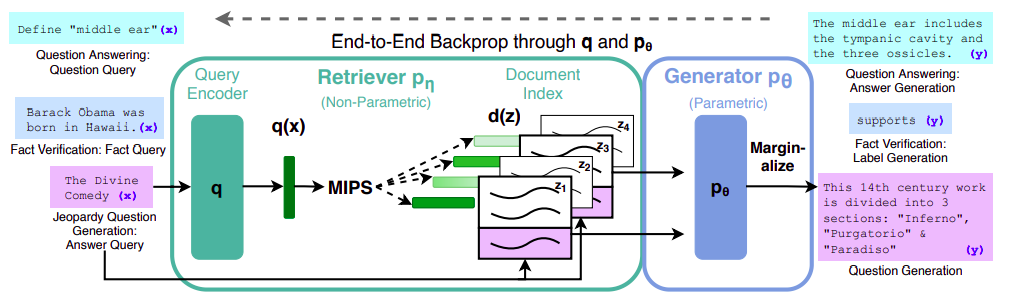 Source: Original Paper
Source: Original Paper
Motivation
There are tons of tutorials over the internet on how to build a RAG pipeline, the issue is, the majority rely on online services and cloud tools, especially for the generation part, many tutorials advocate for the use of OpenAI LLM APIs, which, unfortunately, are not always free and may not be deemed trustworthy, particularly when handling sensitive data.
That’s why I tried to build an end-to-end RAG api entirely offline and completely free, which can be very useful for companies that don’t want to send their sensitive data over to a cloud service or a blackbox online LLM Api.
Project Overview
We’ll create an API endpoint where users can ask questions. The endpoint will search through a collection of research papers to find the answer. Then, it will use a Large Language Model (LLM) to process the answer and return it in a simple and easy-to-understand format.
 Local RAG Pipeline Architecture
Local RAG Pipeline Architecture
The projects consists of 4 major parts:
- Building RAG Pipeline using Llamaindex
- Setting up a local Qdrant instance using Docker
- Downloading a quantized LLM from hugging face and running it as a server using Ollama
- Connecting all components and exposing an API endpoint using FastApi
Alright, let’s start building the project.

Building the project
We’ll follow the common flow of a RAG pipeline, which is a bit similar to a standard ETL piepline. 
Code for the project can be found in this Github repository. Don’t forget to
1. Loading
First, we need to get some data, in our case, research papers. Let’s create a python script to quickly download papers from arxiv.org using some keywords. Luckily, there’s already a python wrapper for the arxiv api.
The following function is responsible for downloading research papers into a folder.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
def download_papers(self, search_query, download_path, max_results):
self._create_data_folder(download_path)
client = arxiv.Client()
search = arxiv.Search(
query=search_query,
max_results=max_results,
sort_by=arxiv.SortCriterion.SubmittedDate,
)
results = list(client.results(search))
for paper in tqdm(results):
if os.path.exists(download_path):
paper_title = (paper.title).replace(" ", "_")
paper.download_pdf(dirpath=download_path, filename=f"{paper_title}.pdf")
print(f"{paper.title} Downloaded.")
Llamaindex supports variaty of Data Loaders, in our case, our data will be a bunch of PDFs in a folder, which means we can use SimpleDirectoryReader
2. Indexing / Storing
Indexing involves structuring and representing our data in a way that facilitates storage, querying, and feeding to an LLM. Llamaindex provides several methods for accomplishing this task.
Chuncking
Initially, we need to chunk our data using a specified chunk_size. This is necessary because documents can often be too lengthy, which can introduce noise and exceed the context length for our LLM.
Embedding
Next, we proceed to embed these chunks using an pre-trained model. You can learn more about them in my previous article
There are many available powerful pre-trained model to use for embeddings. For this project, we’ll use sentence-transformers/all-mpnet-base-v2  sentence-transformers/all-mpnet-base-v2 on Hugging Face
sentence-transformers/all-mpnet-base-v2 on Hugging Face
Storing
For storing our data, we’ll use a local Qdrant docker instance, which can be easily set up with:
1
docker run -p 6333:6333 qdrant/qdrant
However, since we require our data to persist on disk even after stopping the instance, we must add a volume.
1
docker run -p 6333:6333 -v ~/qdrant_storage:/qdrant/storage:z qdrant/qdrant
qdrant_storageis the name of a folder that we created in our HOME directory where data from qdrant db instance will be saved.
Then we can access our database UI from http://localhost:6333/dashboard
The following function is responsible for loading, chunking, embedding and storing our data.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
def ingest(self, embedder, llm):
print("Indexing data...")
# Loading
documents = SimpleDirectoryReader(self.config["data_path"]).load_data()
client = qdrant_client.QdrantClient(url=self.config["qdrant_url"])
qdrant_vector_store = QdrantVectorStore(
client=client, collection_name=self.config["collection_name"]
)
storage_context = StorageContext.from_defaults(vector_store=qdrant_vector_store)
service_context = ServiceContext.from_defaults(
llm=llm, embed_model=embedder, chunk_size=self.config["chunk_size"]
)
# Chunking + Embedding + Storing
index = VectorStoreIndex.from_documents(
documents, storage_context=storage_context, service_context=service_context
)
print(
f"Data indexed successfully to Qdrant. Collection: {self.config['collection_name']}"
)
return index
The full code of
Dataclass can be found here: data.py
We can see that our collection is now created
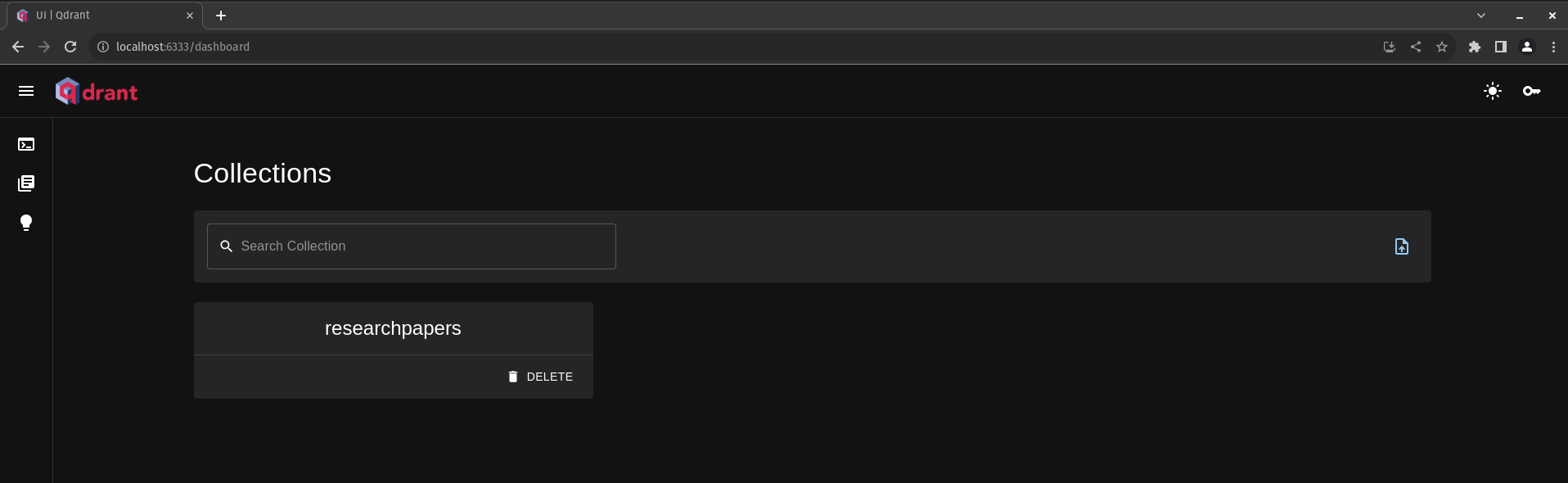 Qdrant dashboard UI
Qdrant dashboard UI
3. Querying
Now that we’ve successfully loaded our data (research papers) into our vector store (Qdrant), we can begin querying it to retrieve relevant data for feeding to our LLM.
Let’s begin by crafting a function that sets up our Qdrant index, which will serve as our query engine.
Query Engine
1
2
3
4
5
6
7
8
9
10
11
12
13
def qdrant_index(self):
client = qdrant_client.QdrantClient(url=self.config["qdrant_url"])
qdrant_vector_store = QdrantVectorStore(
client=client, collection_name=self.config['collection_name']
)
service_context = ServiceContext.from_defaults(
llm=self.llm, embed_model=self.load_embedder(), chunk_size=self.config["chunk_size"]
)
index = VectorStoreIndex.from_vector_store(
vector_store=qdrant_vector_store, service_context=service_context
)
return index
Code from: rag.py
LLM
The goal is to use a local LLM, which can be a bit challenging since powerfull LLMs can be resource heavy and expensive. But thanks to model quantization, and Ollama, the process can be very easy.
Please refer to my previous article to learn more about setting up a local LLM with Ollama: Use custom LLMs from Hugging Face locally with Ollama
After downloading zephyr-7b-beta.Q5_K_M.gguf from Hugging Face, we need to create a Modelfile for Ollama.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
FROM models/zephyr-models/zephyr-7b-beta.Q5_K_M.gguf
PARAMETER num_ctx 3900
PARAMETER temperature 0.7
PARAMETER top_k 50
PARAMETER top_p 0.95
PARAMETER stop "<|system|>"
PARAMETER stop "<|user|>"
PARAMETER stop "<|assistant|>"
PARAMETER stop "</s>"
TEMPLATE """
<|system|>\n system
{{ .System }}</s>
<|user|>\n user
{{ .Prompt }}</s>
<|assistant|>\n
"""
SYSTEM """
As a personal assistant for researchers, your task is to analyze the provided research papers and extract pertinent information on using the provided keywords. Summarize key findings, methodologies, and any notable insights. This assistant plays a crucial role in facilitating researchers' understanding of the current state of knowledge on the provided keywords.
Your Motive:
Give the learner "aha" moment on every Topic he needs to understand. You can do this with the art of explaining things.
Focus on Conciseness and Clarity: Ensure that the output is concise yet comprehensive. Focus on clarity and readability to provide researchers with easily digestible insights.
IMPORTANT:
If the user query cannot be answered using the provided context, do not improvise, you should only answer using the provided context from the research papers.
If the user asks something that does not exist within the provided context, Answer ONLY with: 'Sorry, the provided query is not clear enough for me to answer from the provided research papers'.
"""
Next, we create our model using the Modelfile.
1
ollama create research_assistant -f Modelfile
Then, we start the model server:
1
ollama run research_assistant
By default, Ollama runs on http://localhost:11434
Finally, we create an API endpoint using FastAPI. This endpoint will receive a query, search the documents, and return a response.
An advantage of using FastAPI is its compatibility with Pydantic, which is very helpful in structuring our code and API responses.
Let’s begin by defining two models: one for the Query and one for the Response:
1
2
3
4
5
6
7
8
class Query(BaseModel):
query: str
similarity_top_k: Optional[int] = Field(default=1, ge=1, le=5)
class Response(BaseModel):
search_result: str
source: str
After initiating the llm, qdrant index and our FastAPI app:
1
2
3
4
5
6
llm = Ollama(model=config["llm_name"], url=config["llm_url"])
rag = RAG(config_file=config, llm=llm)
index = rag.qdrant_index()
app = FastAPI()
We’ll create a route that receives a Query and returns a Response, as defined in our pydantic classes.
1
2
3
4
5
6
7
8
9
10
11
a = "You can only answer based on the provided context. If a response cannot be formed strictly using the context, politely say you don’t have knowledge about that topic"
@app.post("/api/search", response_model=Response, status_code=200)
def search(query: Query):
query_engine = index.as_query_engine(similarity_top_k=query.similarity_top_k, output=Response, response_mode="tree_summarize", verbose=True)
response = query_engine.query(query.query + a)
response_object = Response(
search_result=str(response).strip(), source=[response.metadata[k]["file_path"] for k in response.metadata.keys()][0]
)
return response_object
Code from: app.py
Regarding the config file used throughout the project:
1
2
3
4
5
6
7
data_path: "data/"
llm_url: "http://localhost:11434"
llm_name: "research_assistant"
embedding_model: "sentence-transformers/all-mpnet-base-v2"
qdrant_url: "http://localhost:6333"
collection_name: "researchpapers"
chunk_size: 1024
Now, Let’s try the api with the following request:
1
2
3
4
{
"query": "How can robots imitate human actions?",
"similarity_top_k": 3
}
For testing purposes, we’ll just use the docs UI that comes with FastAPI out of the box
 API Request
API Request
Response  API Response
API Response
Great! The api was able to retreive relevant context from our documents to return a well structured answer alongside citing the sources.
Conclusion
In summary, the project’s goal was to create a local RAG API using LlamaIndex, Qdrant, Ollama, and FastAPI. This approach offers privacy and control over data, especially valuable for organizations handling sensitive information.
Don’t forget to visit the project Github repository